After Once Again Losing a Football Game
Question
After once again losing football game to the college'south = arch rival, the alumni association conducted a survey to see if alumni were in favor of firing the jitney: An SRS of 100 alumni from the population of all living alumni was taken. Threescore-four of the alumni in the sample were in favor of firing the motorcoach: Let p correspond the proportion of all living alumni who favor firing the motorcoach;Suppose yous wish to encounter if the majority of alumni are in favor of firing the coach: To do this you test th
Later on one time again losing football game to the college'south = arch rival, the alumni association conducted a survey to see if alumni were in favor of firing the coach: An SRS of 100 alumni from the population of all living alumni was taken. 60-four of the alumni in the sample were in favor of firing the motorbus: Permit p stand for the proportion of all living alumni who favor firing the coach; Suppose yous wish to see if the bulk of alumni are in favor of firing the jitney: To exercise this you lot test the hypotheses HO: p 0.50,Ha: p 0.l The P-value of your test is between .05 and x between .01 and.05 betwixt .001 and .01 below .001

Answers
Subsequently one time over again losing a football game game to the archrival, a college's alumni association conducted a
survey to see if alumni were in favor of firing the coach. An SRS of 100 alumni from the population
of all living alumni was taken, and 64 of the alumni in the sample were in favor of firing the coach.
Suppose you lot wish to see if a majority of living alumni are in favor of firing the coach. The appropriate examination statistic is
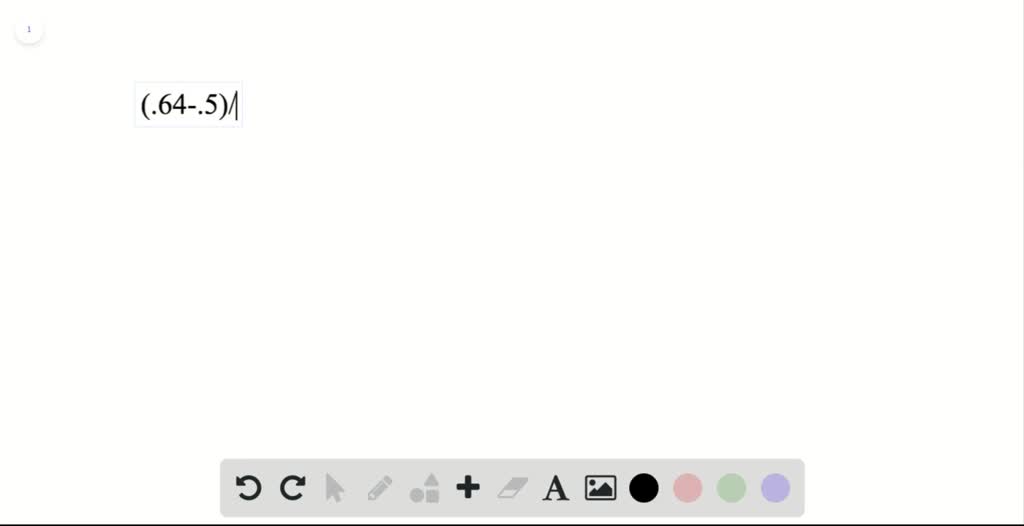
(a) $z=\frac{0.64-0.v}{\sqrt{\frac{0.64(0.36)}{100}}}$ (d) $z=\frac{0.64-0.5}{\sqrt{\frac{0.64(0.36)}{64}}}$
(b) $t=\frac{0.64-0.5}{\sqrt{\frac{0.64(0.36)}{100}}} \quad$ (e) $z=\frac{0.5-0.64}{\sqrt{\frac{0.5(0.5)}{100}}}$
(c) $z=\frac{0.64-0.5}{\sqrt{\frac{0.five(0.5)}{100}}}$
A archetype story involves 4 carpooling students who missed a test and gave an excuse that they had a flat tire on the makeup test. The instructor asked students to place which tire went apartment. If they actually didn't take a apartment tire, would they be able to identify the aforementioned tire? And so the author decided he was going to run a an experiment, and the author asked 41 other students toe identify the tire that they would select, and some of them said left front end. Others said right front. Some said Left rear and others said Right rear. And the information that was collected was that eleven people said Left front fifteen said Correct Front viii said left rear, and vi said Right rear. Now that totals upward to Onley 40. Fifty-fifty though he asked 41 students, one of the students said That spare tire, So nosotros're gonna leave that out of our information. So this author is making a claim and he believes that the results fit a uniformed distribution. So in guild for us to examination this claim, nosotros're going to have to construct are zero hypothesis and our culling hypothesis, and you lot're no hypothesis when yous're trying to determine whether observed data fits something that is expected, the argument of fit becomes your nix hypothesis. So therefore, our claim is going to exist our zippo hypothesis. Then our alternative hypothesis is going to exist that the results practise not fit a uniformed distribution. Mhm. And the hypothesis test that we're going to run is going to exist a chi foursquare goodness of fit examination, which requires u.s. to generate a chi square test statistic for our information. And nosotros will have to apply the formula some of observed, minus expected quantity squared, divided by expected. So let's go support to our information, and the information that nosotros've collected would be classified, as are observed data. Aye, and so at present we demand to summate are expected values. And if there were 40 people involved and nosotros would expect a uniformed distribution, that means we would look each response to go 10 people so we would await tend to say left forepart, tend to say correct front, tend to say left rear and tend to say right rear. And so nosotros're now ready to calculate our chi foursquare test statistic, and then we're going to add on to our chart An additional column and we're going to phone call that column oh minus e quantity squared, divided by due east. So we'll have the observed value minus the expected value. Nosotros'll go a difference of one. We're going to square that So it's still 1/ten, which is that expected value. Then we'd get 0.1 then nosotros'll practice 15 minus 10. We get a issue of five when we square it. It's 25 divided by the expected value of 10. Yields a value of 2.five. Do the aforementioned thing for left rear eight. Minus 10 is negative two. Only when we square information technology, it'southward positive. Four, divided past the expected value of 10, resulting in 0.iv and and so half dozen minus x would be negative. 4. When nosotros square that we get positive 16/10 or ane.half-dozen now to calculate the Chi Square examination statistic, nosotros volition have to add up these values. And when we add upward those values, our Chi Square test statistic is iv.half dozen now. Some other component of the hypothesis exam is to summate our P value, and R P value is referring to the probability that Chi Foursquare is greater than the test statistic we just found. Now, to get a better sense of what that's about, we're going to draw a chi square Distribution and chi square distributions are skewed to the right, and their shape is dependent on the degrees of freedom, and our degrees of liberty can be found by doing G minus one. And One thousand represents the number of categories which you lot've separated your data into. If we go back to our chart, you lot tin can see nosotros take separated our data into iv dissimilar categories, corresponding with the four different tires on the vehicle. So if K is four, then our degrees of liberty will be iii. Not merely does the degrees of freedom betoken the shape of the graph, but the degrees of freedom also is equivalent to the hateful of that chi square distribution. And so on our picture we could place the mean, which will exist establish slightly to the correct of the peak on the Chi Square centrality. Now, for us to detect our P value, nosotros're trying to figure out what'due south the probability that Chi square is greater than 4.6. So we're trying to determine this shaded region, and in order to practice then, the most effective mode is to utilize your chi squared cumulative density part in your graphing calculator, and any time you utilise that function, y'all have to provide the lower boundary of the shaded expanse, the upper boundary of the shaded expanse and the degrees of liberty. So for our data, the lower boundary is the exam statistic, the upper boundary. If you lot imagine that curve continuing infinitely to the correct, you're going to get to some extremely high values of Chi Square. And so we're going to utilize ten to the 99th Power to represent our upper limit, and our degrees of liberty was three. So let me testify yous where you can find that chi squared cumulative density function. So I'1000 bringing in my calculator and I'chiliad going to hit the second button and the variables button and select number eight. Nosotros're going to put the low boundary of the shaded area, the upper boundary of the shaded area, followed by my degrees of freedom, and I finish upwardly with a P value off approximately point 2035 At present there'south one more component of a hypothesis exam that we could find and that is chosen your chi square critical value. And to determine that chi square critical value, we're going to await in the back of your textbook. Y'all will find a chi square distribution tabular array and downwardly the left side of the table, you'll discover degrees of freedom and across the top of the table, y'all will notice levels of significance, and levels of significance are denoted by the Greek letter Alfa. And nosotros want to run this hypothesis exam at a level of significance of 0.5 So we will locate 0.5 across the top of the chart and our degrees of freedom down the side of the chart and where the to represent or run across up is your chi square critical value, and they meet upwards at 7.815 So allow'southward recap the three components that we have plant so far we have found the Chi Square test statistic to be 4.6. We have found the P value to be point 2035 and we accept found our chi square critical value to be 7.815 So what practice we practice with these values to make a decision about that claim. So when it comes fourth dimension to make your decision, you lot can either utilize the P value or you tin can use the chi square critical value. Yous practice not need to do both. I'chiliad going to show yous both and so you can make a determination of which method you prefer. In order to use the P value. You're going to compare your level of significance to your P value. And if your level of significance is greater than your P value than your decision is to decline the null hypothesis. So let's run our exam. So our level of significance was 05 and we constitute RPI value to exist 0.2035 So we could say that Alfa is not greater than the P value. So therefore our conclusion will be fail to reject the no hypothesis. Let me show you how you tin utilise the critical value to get in at that aforementioned decision. To use the critical value, I recommend cartoon out some other chi square distribution and placing your critical value on that curve. And by placing that on the curve, you have broken your graph into 2 parts. You have the tail which we're going to ascertain as the decline, the zippo hypothesis region. And then the other office of the graph is going to exist determined or called our neglect to reject the zippo hypothesis region and you're then going to look at your calculated Chi Square test statistic and nosotros establish our Chi Square exam statistic to exist a 4.vi. So if 7.8 is correct hither, then 4.6 would fall back hither, which is in the fail to reject region. So once more, nosotros end up with the decision that nosotros will neglect to reject the null hypothesis. So if nosotros go back to our statements, we are not able to reject this statement. So that's saying it could be true. It might exist true. Information technology might not be true, but our evidence don't support throwing it away. So therefore, our conclusion there is insufficient testify to reject the claim that the results fit a uniforms distribution again. We don't take enough to throw it away, but nosotros don't Nosotros're non saying we support it, either. It's only the data is inconclusive and that concludes your hypothesis test
And then for this question, we would exist assuming for Arnold hypothesis that that the hateful weight loss is zilch, and that alternately, the main weight loss is higher than goose egg. They got an X bar of £3 that was for a sample size of 40 people on the weight watchers and the standard deviation was £4.ix Then quite a large standard divergence. And nosotros want to examination the merits uh and they claim that it's a college than zero, but we want to examination this at a one% significance level, So nosotros're going to assume that the hateful is zero, and how probable is it to get that mean weight of £3 or more extreme than that, if the mean is actually nothing. And then we want to find the likelihood of getting an 10 bar that is greater than or equal to £3. Then we demand to catechumen that to a T value and it will take 39 degrees of freedom, and we do that past taking three minus the mean divided by that standard divergence of the X. Confined which is that 4.9 divided by the square root of 40. And this will be our test statistic. Let's observe out what that test statistic is. So I take three divided past a left parenthesis. Due east iv.ix divided past the foursquare root of 40. And he ended up getting that examination statistic mm is equivalent to 3.872 At present we need to find what that p value is. This p value, you tin can also find the critical T value but let's find the p value when we're testing it at the ane% significance level. So I'm going to use my software and I'thou going to use that T C D. F push button and the T c D F button second and distribution and mighty CDF. And I'yard going to plug in that 3.872 as the low number iii point 872 And my upper I'm going to put in simply a large number like 1000 10,000 100 would actually exist fine. And then there are degrees of freedom is 39. And and so I find that value is very very small. It's 0.ii And so since that value is less than ane% which is our significance level, we have definitely have prove, nosotros take show to refuse them all and all hypothesis that's supposed to exist a you and therefore nosotros would claim that the mean weight loss mean weight loss yeah is greater than £0. At present we're not going to say it'southward £3. We're simply going to say it's greater than £0. So it is considered to be significant. It is significantly college
27. Each note is that new is bigger than equal to 32. Which one is The new is pocket-size, circumspect to determinative value, which is expired minus a note over standard divergence over square root. A van, which is 30.1667 minus 32 over four betoken or 37 over squared off 18, which is equal to negative one.943 for the P value if the b value. Only we consume information technology every value you call back. Table five with caste or freedom, equal toe end minus 1. So the P value according and so these inputs is between open or 25 and open or 5. Uh, if the value is smaller than significance level non, I possibly rejected. And so me hither is smaller than opened or five. And so we reject they're not hypothesis. So for the if we can say that there is sufficient sufficient show to back up the clean
This question were asked to identify the population and sample based on different scenarios and tell whether or non they tin exist used to create a confidence interval. So let's start get-go off by just defining the variables. Then we have P, which is the population proportion and P hot, which is the symptom, the sample proportion. So in taste A our population volition be all the cars, whereas the sample size is going to exist the cars stopped at the sure checkpoints and similar we said, p as the population proportion. Then in this example, is all cars with safe problems, and P hot is a sample proportion. And then these air the cars that are actually seen with condom issues. So we can farther summate P hat past using the numbers given. And we know that there are xiv of 134 cars stopped have at least one rubber problem, and then that number ends up being 0.1045 Weaken farther transfer that into percentage form and we get that information technology'due south 10 points 45% as RP hot volume and were also asked whether these methods tin can be used to create the conviction interval. So when a sample of data is representative, then information technology tin be used to create a confidence interval and in this case it is because it'due south sampling all cars. For case be, we are going to find the population and sample one time once more for the population. Nosotros have the general public and for the sample, it's people that are logged into the website. Nosotros can further define them as P being the favor. The people in favor of prayer in school where united states The sample proportion are the people that voted in this poll who favor prayer in school, we tin calculate p hot with the given values were at 488 over 602. We get 0.81 and making that into a per centum value, we get 81% toe. Decide whether or not the sample tin be used. We can Onley consider people logging into the website for this case. So in a way it's a bit biased and not random. So you're unable to apply the methods to create the confidence interval in Casey. The population is the parents at school and the sample is the parents expressing opinions through the question hither. So the population proportion are all parents who favor the uniforms, whereas the sample proportion P hat are the respondents favoring uniforms. Nosotros can summate the P hot value based on the numbers given 228 over 380 and that gives us a value of 0.half-dozen that can be converted into a percentage of sixty%. And since in that location were 1245 surveys sent home but only 380 returned, there is a complication of non response bias. And and so y'all would use these methods with caution if creating a confidence interval. And the last role D were given a population of students at higher, and the sample size is the xvi 31,632 College admits the population proportion are all the students who will graduate on time and P hot the sample proportion as the students graduating on time that year. Then based on the given values, we take 1388 over 632. Really, this number is supposed to be xvi 32. Sorry, and then based on that we become a value of 0.85 and that could be converted to 85% based on this value, and the sample data for this case was pretty representative. And so since information technology is representative, you can employ these methods to create a confidence interval.
Similar Solved Questions
Source: https://itprospt.com/num/4375747/after-once-again-losing-football-game-to-the-college-x27
{kind=link}
Post a Comment for "After Once Again Losing a Football Game"